Collapse Becomes Observable
ACR monitors reward variance already computed during GRPO, exposing batches where gradients are effectively wasted.
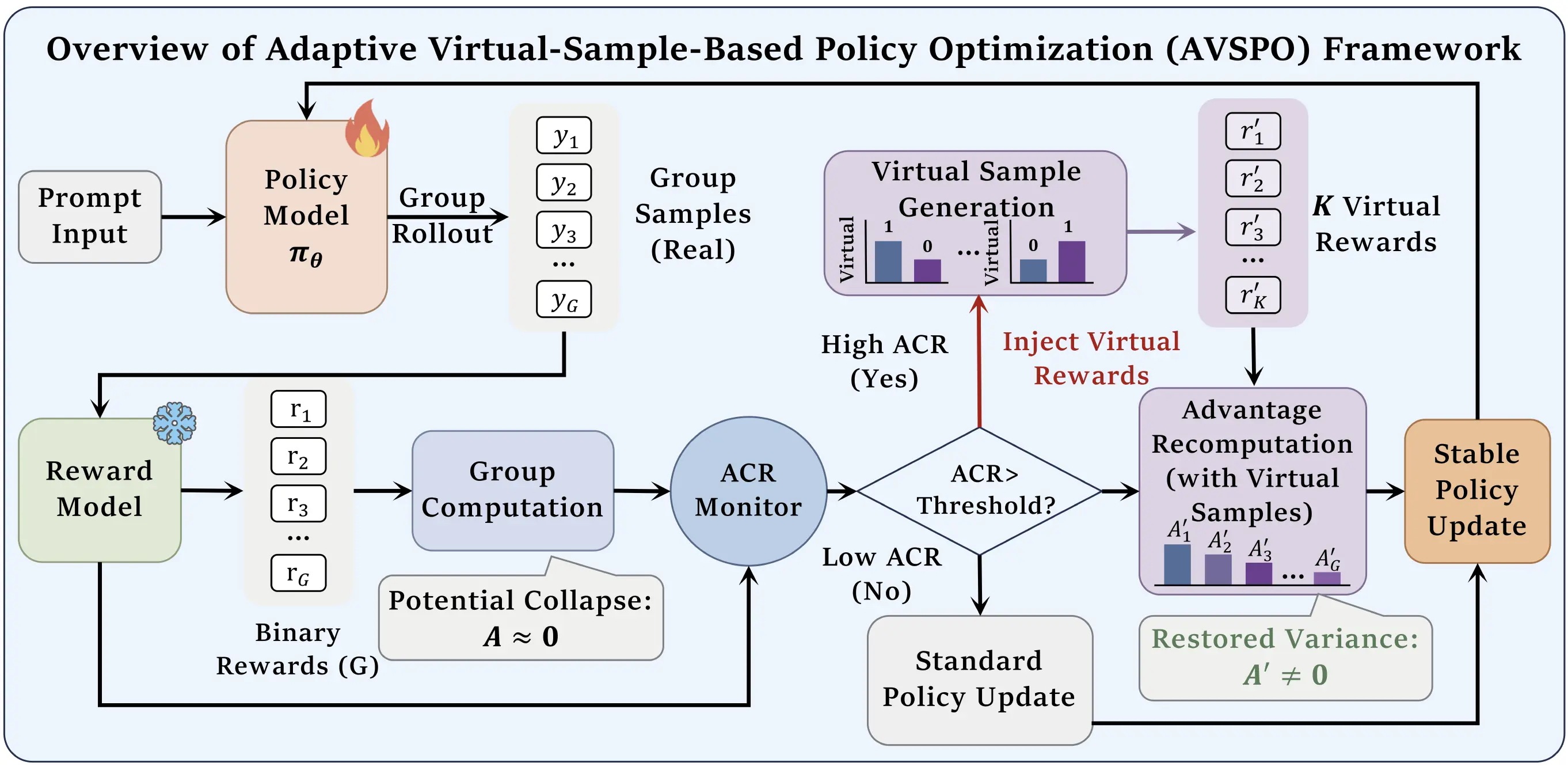
AVSPO turns homogeneous reward groups from wasted GRPO updates into usable training signal through real-time collapse diagnosis and virtual reward samples.
Group Relative Policy Optimization (GRPO), a prominent algorithm within Reinforcement Learning from Verifiable Rewards (RLVR), has achieved strong results in improving the reasoning capabilities of large language models. However, GRPO is prone to advantage collapse: when all responses in a group receive homogeneous rewards, such as all correct or all incorrect answers, the group produces near-zero advantages and vanishing gradients.
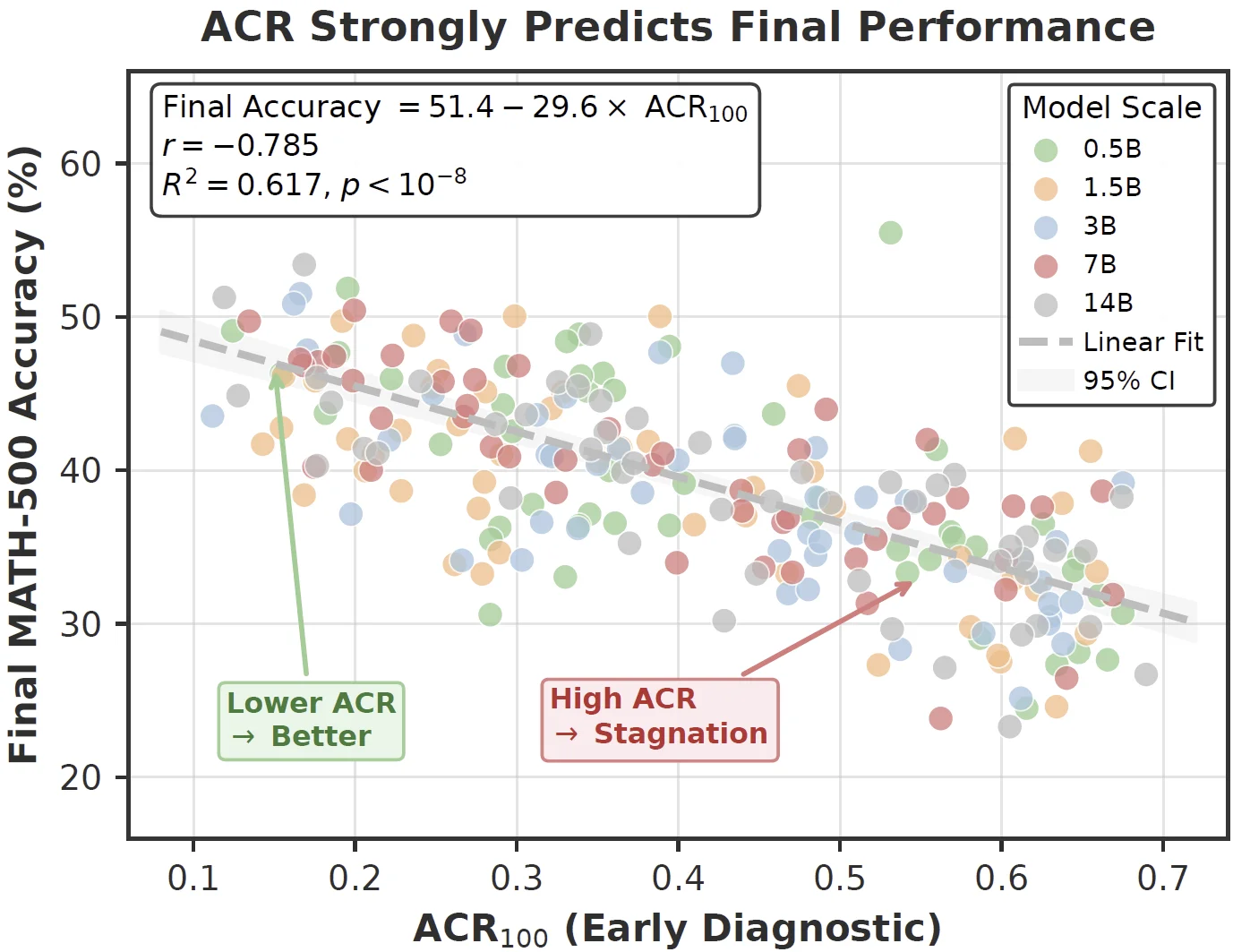
This work introduces the Advantage Collapse Rate (ACR), a diagnostic metric that quantifies the proportion of training batches with ineffective gradients. Across models from 0.5B to 14B parameters on mathematical reasoning benchmarks, early ACR strongly predicts training stagnation and final performance.
We propose Adaptive Virtual Sample Policy Optimization (AVSPO), a lightweight extension of GRPO that injects virtual reward samples guided by real-time ACR monitoring. AVSPO enables learning from homogeneous groups without additional rollouts, reducing collapse by 58-63% relative to GRPO and yielding consistent accuracy gains of 4-6 percentage points across model scales.
The paper reframes a hidden GRPO failure mode as a measurable training signal.
ACR monitors reward variance already computed during GRPO, exposing batches where gradients are effectively wasted.
Across 245 configurations, early ACR explains 62% of final MATH-500 performance variance, allowing poor settings to be detected before long training runs finish.
AVSPO adds synthetic reward values to normalization statistics only. The virtual samples do not contribute policy gradients.
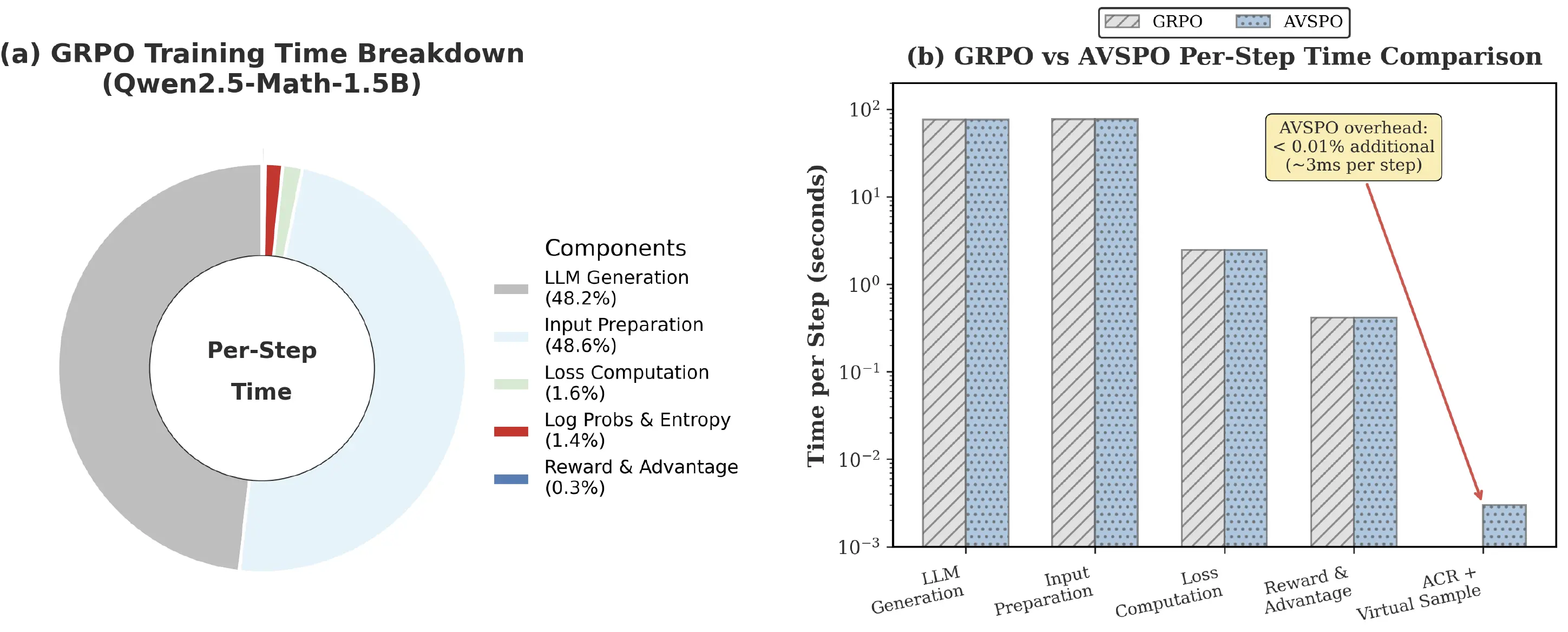
The algorithm keeps the same per-iteration complexity as GRPO and adds less than 0.01% measured overhead in the reported profiling.
Advantage collapse occurs whenever within-group reward variance vanishes. In binary RLVR tasks, this happens in two symmetric regimes: uniformly failed groups on hard problems and uniformly solved groups on easy problems. Both cases produce no useful GRPO advantage despite valid verifier feedback.
A minimal intervention at the reward-statistics level, designed to preserve GRPO's critic-free efficiency.
For each prompt, GRPO samples G responses and receives binary rewards from the verifier.
ACR is computed from group-level reward standard deviations in the current training batch.
When ACR exceeds the adaptive threshold, AVSPO adds K virtual reward samples to collapsed groups.
Only real samples receive gradients; virtual rewards restore variance for advantage normalization.
The number of virtual samples scales with collapse severity. The paper uses α = 0.5 and an adaptive trigger threshold, balancing under-intervention against excessive augmentation.
All methods are trained for 500 steps on Level3-500 with G = 8 and T = 1.0, then evaluated on seven benchmarks.
| Model | GRPO ACR | AVSPO ACR | GRPO Avg. | AVSPO Avg. | Gain |
|---|---|---|---|---|---|
| Qwen2.5-0.5B | 0.45 | 0.18 | 16.5 | 21.0 | +4.5 |
| Qwen2.5-3B | 0.37 | 0.14 | 27.9 | 32.2 | +4.3 |
| Qwen2.5-3B-Instruct | 0.35 | 0.13 | 39.7 | 43.4 | +3.7 |
| Qwen2.5-14B | 0.28 | 0.11 | 49.9 | 54.5 | +4.6 |
| Qwen2.5-Math-1.5B | 0.40 | 0.15 | 33.5 | 39.6 | +6.1 |
| Qwen2.5-Math-7B | 0.33 | 0.14 | 42.2 | 45.9 | +3.7 |
ACR responds predictably to model capacity, sampling temperature, group size, and problem difficulty.
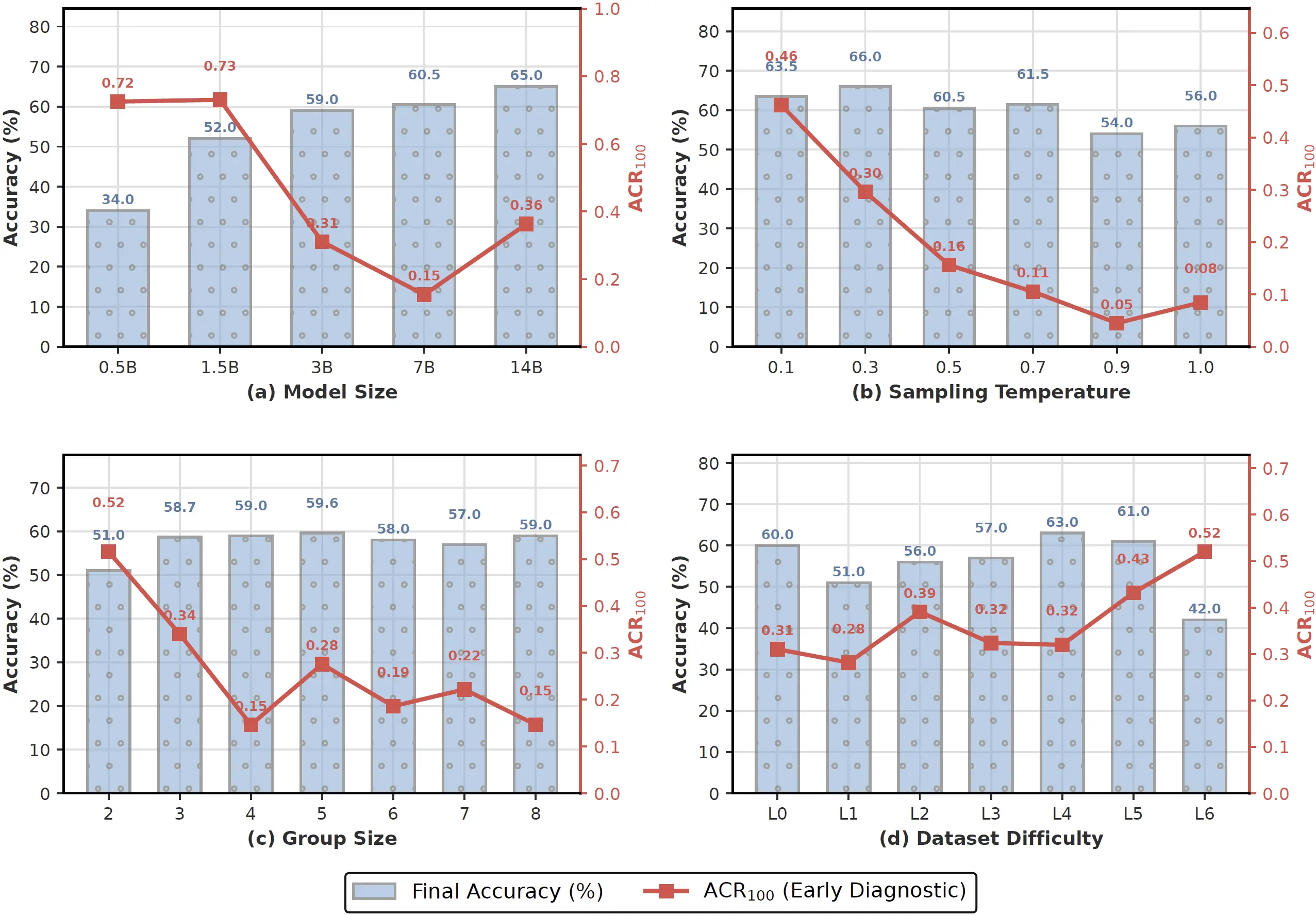
Larger models tend to reduce ACR, while task-model matching still matters; the 7B setting reaches lower ACR than 14B in the reported sensitivity study.
Higher sampling temperature lowers ACR, but accuracy peaks at moderate temperatures because excessive randomness harms solution quality.
Very easy and very hard problems both cause homogeneous rewards. Intermediate difficulty yields the most useful reward diversity.
AVSPO operates entirely on reward statistics. In the reported profiling for Qwen2.5-Math-1.5B, LLM generation and input preparation account for more than 96% of computation. ACR monitoring and virtual sample generation add roughly 3 ms per step, less than 0.01% overhead.
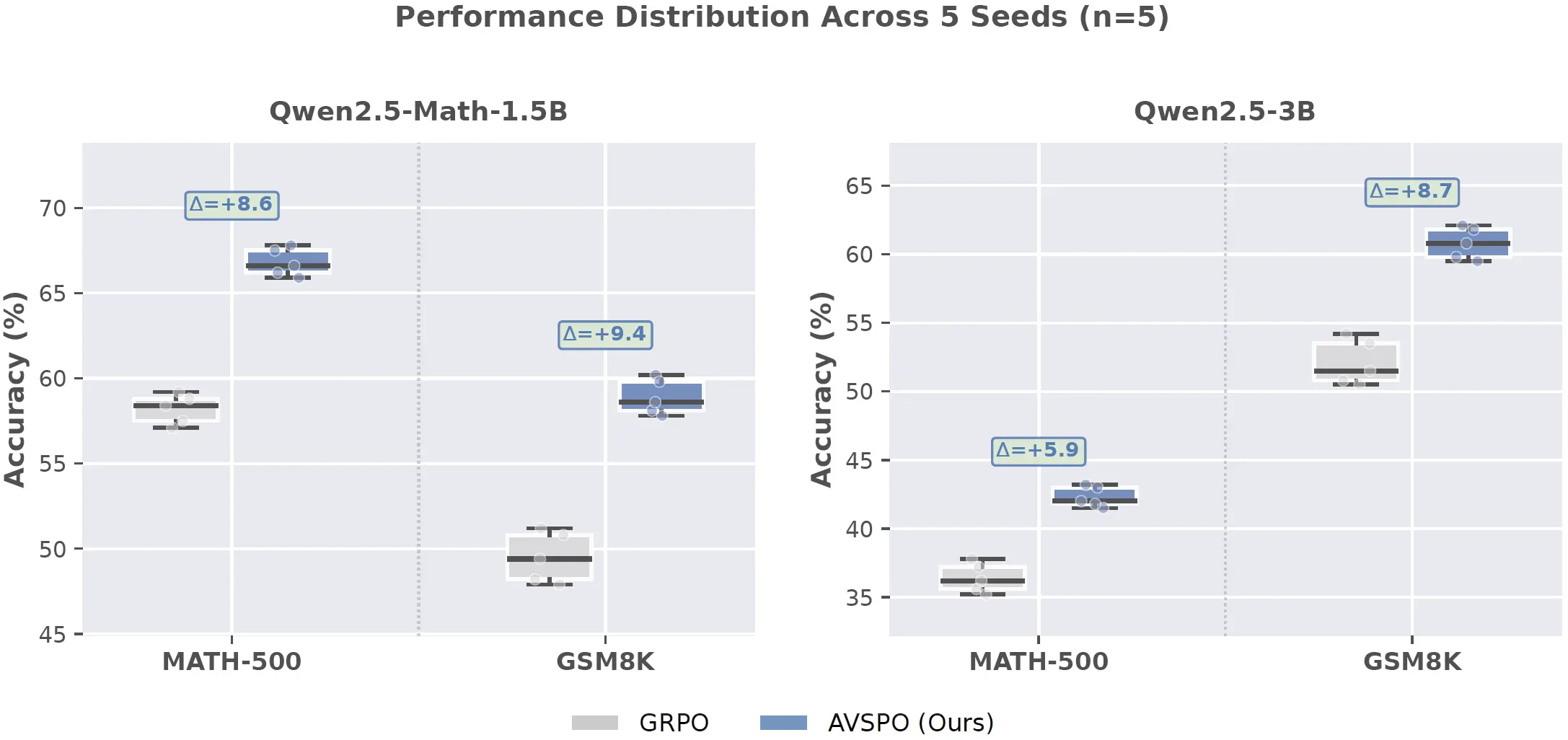
Representative multi-seed experiments show non-overlapping GRPO and AVSPO performance distributions.
Author order follows the project specification.

National University of Defense Technology

National University of Defense Technology

National University of Defense Technology

National University of Defense Technology

National University of Defense Technology
Intelligent Game and Decision Lab, Beijing

The Chinese University of Hong Kong, Shenzhen

Intelligent Game and Decision Lab, Beijing
For questions about the paper, method, evaluation, or project page, please reach out to the corresponding author.
We welcome questions about AVSPO, advantage collapse in GRPO/RLVR training, and potential collaboration opportunities in reinforcement learning from verifiable rewards. For code release or project-page updates, please reach out directly.
@inproceedings{he2026avspo,
title = {Advantage Collapse in Group Relative Policy Optimization: Diagnosis and Mitigation},
author = {He, Xixiang and Sun, Qiyao and Cheng, Ao and Li, Xingming and Ji, Xuanyu and Lu, Hailun and Huang, Runke and Hu, Qingyong},
booktitle = {International Conference on Machine Learning},
year = {2026}
}Visitors Around the World
