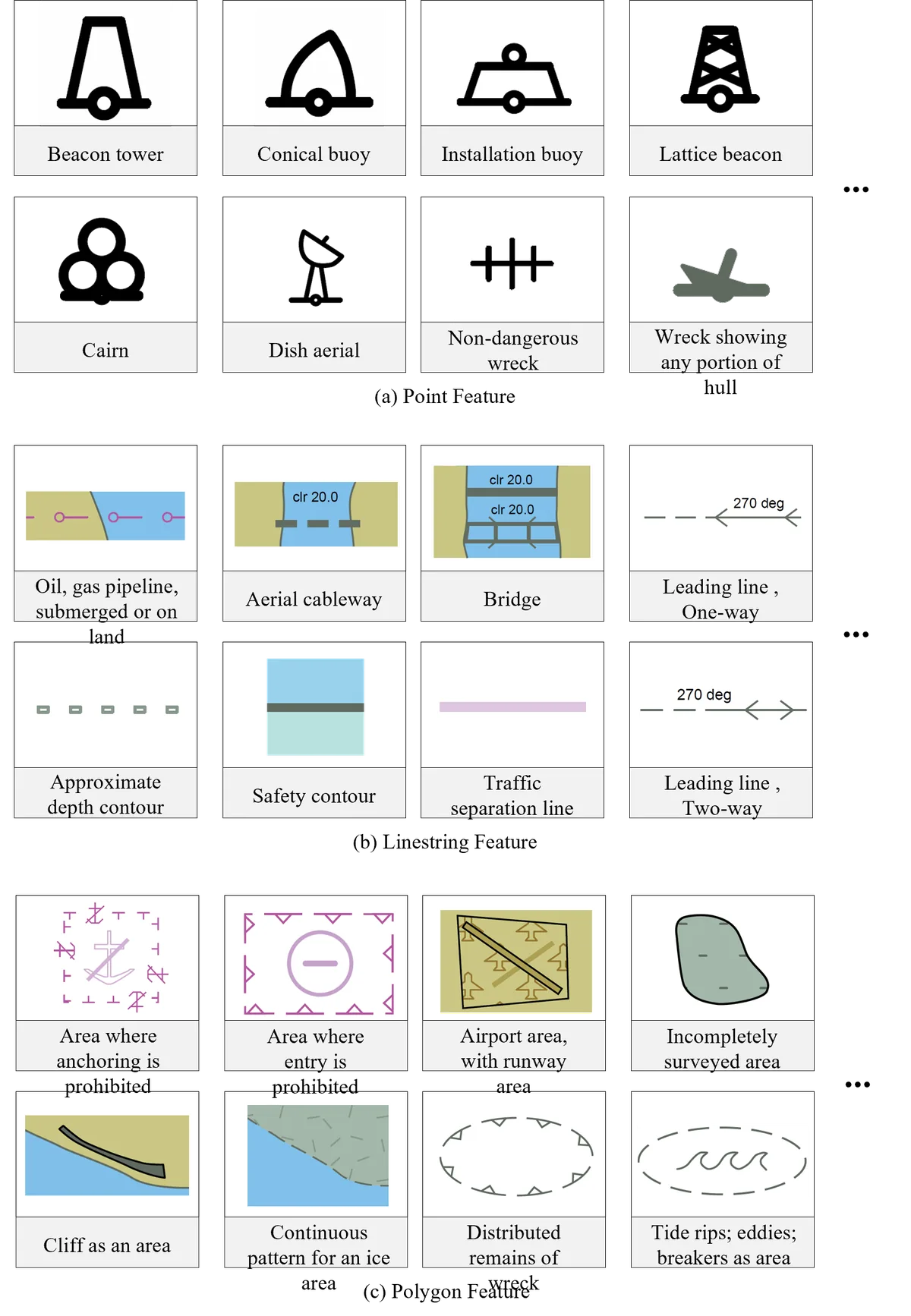
Electronic Navigational Charts (ENCs) are the safety-critical backbone of modern maritime
navigation, yet it remains unclear whether multimodal large language models (MLLMs) can
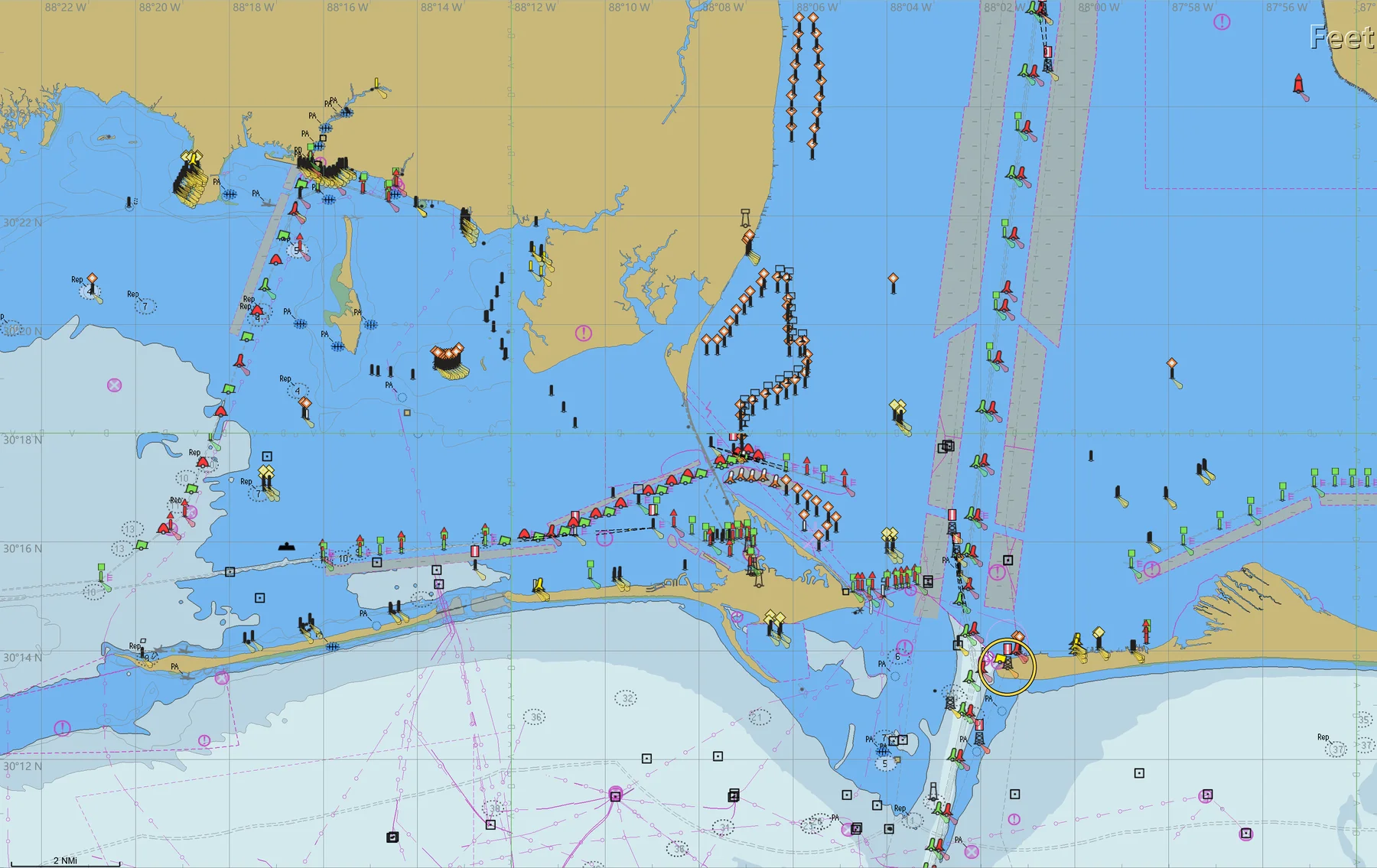
reliably interpret them. Unlike natural images or conventional charts, ENCs encode
regulations, bathymetry, and route constraints via standardized vector symbols,
scale-dependent rendering, and precise geometric structure — requiring specialized
maritime expertise for interpretation.
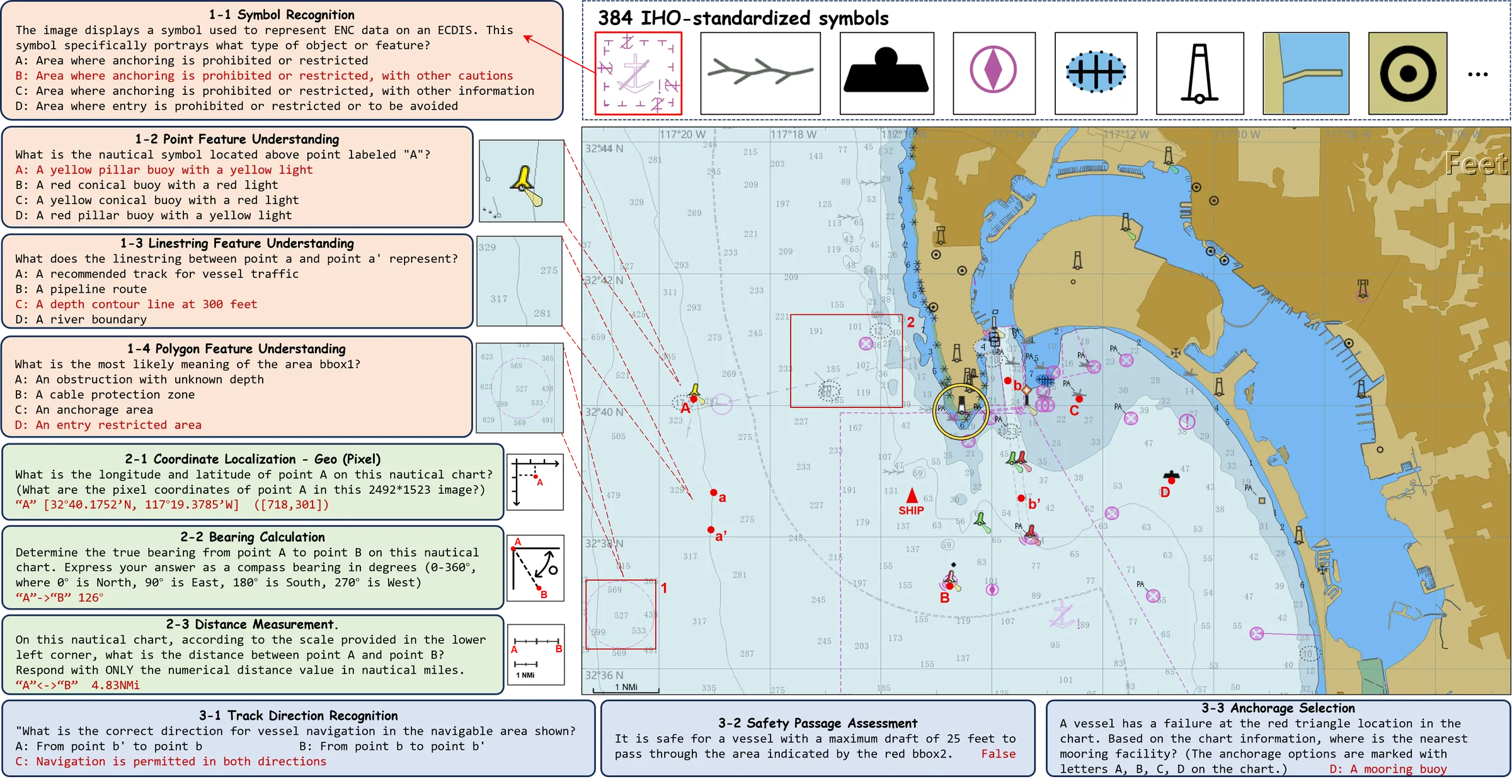
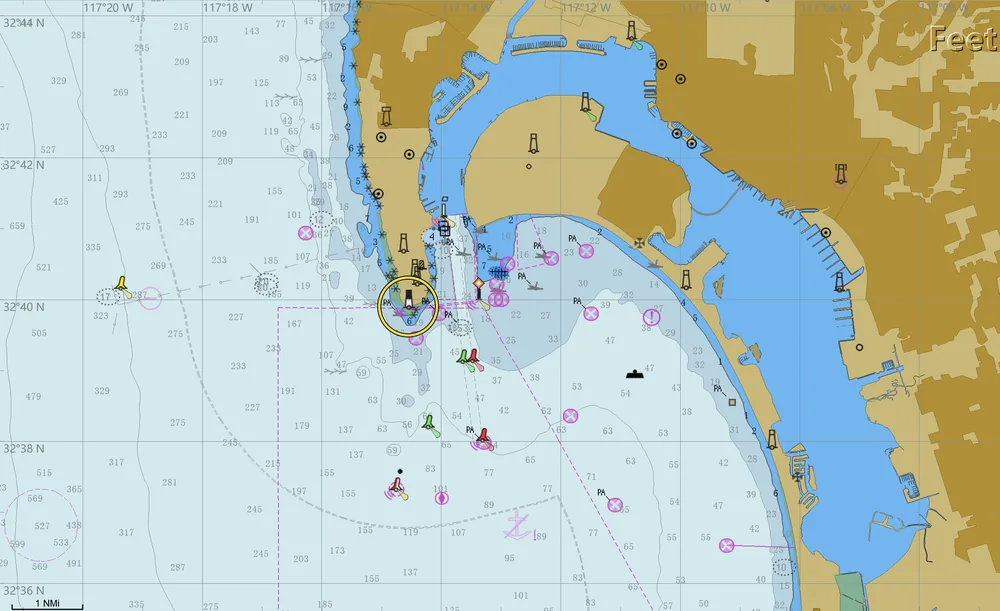
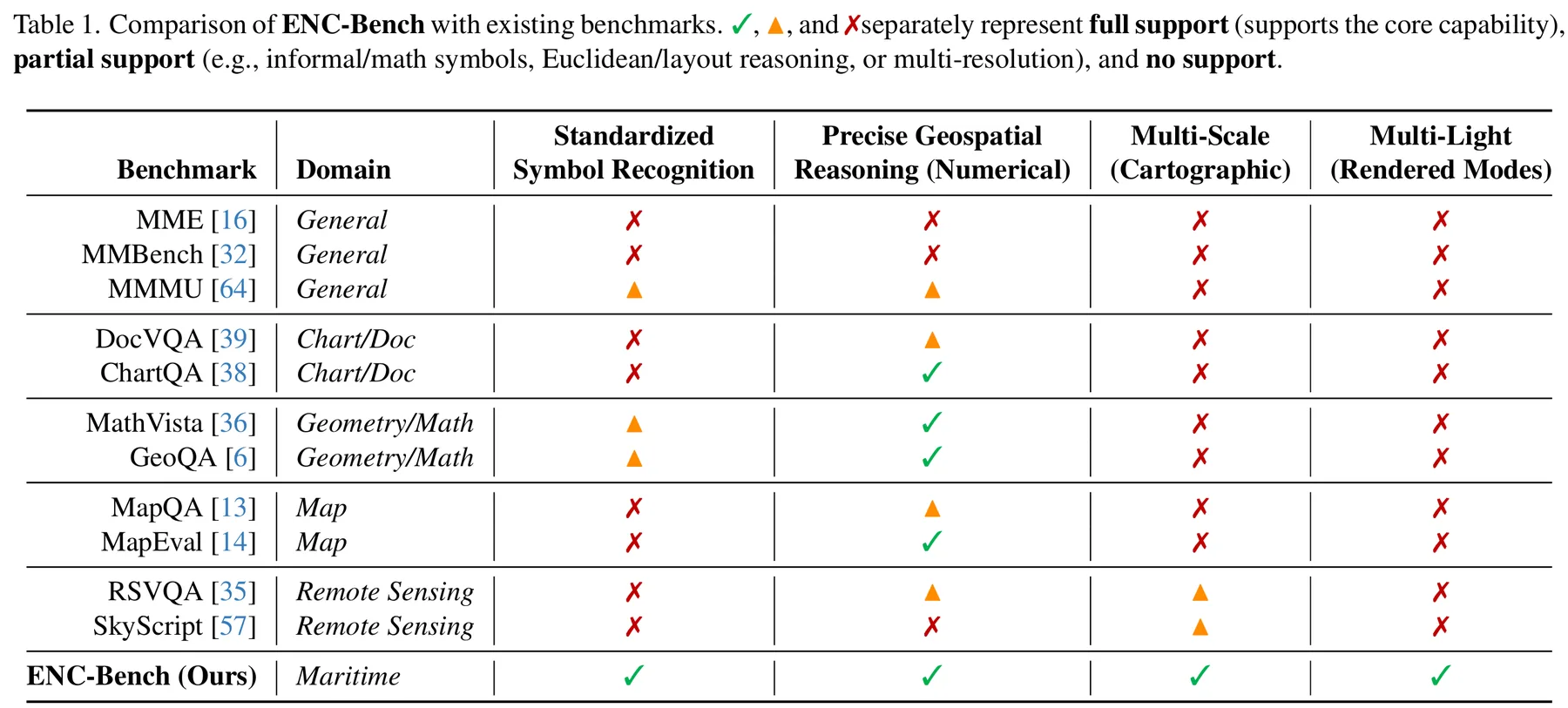
We introduce ENC-Bench, the first benchmark dedicated to professional
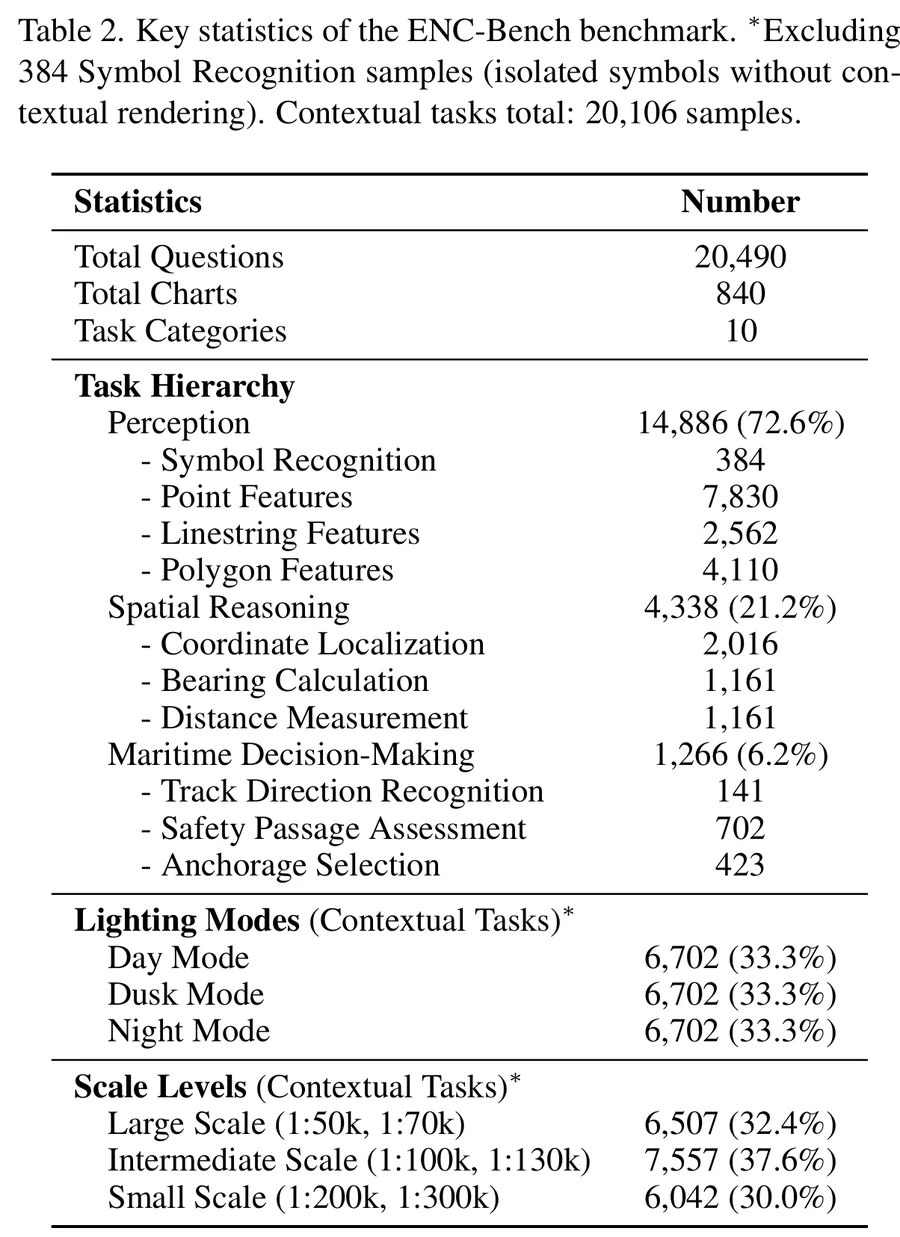
ENC understanding. ENC-Bench contains 20,490 expert-validated samples
from 840 authentic NOAA ENCs, organized into a three-level hierarchy:
Perception (symbol and feature recognition), Spatial Reasoning
(coordinate localization, bearing, distance), and Maritime Decision-Making
(route legality, safety assessment, emergency planning under multiple constraints).
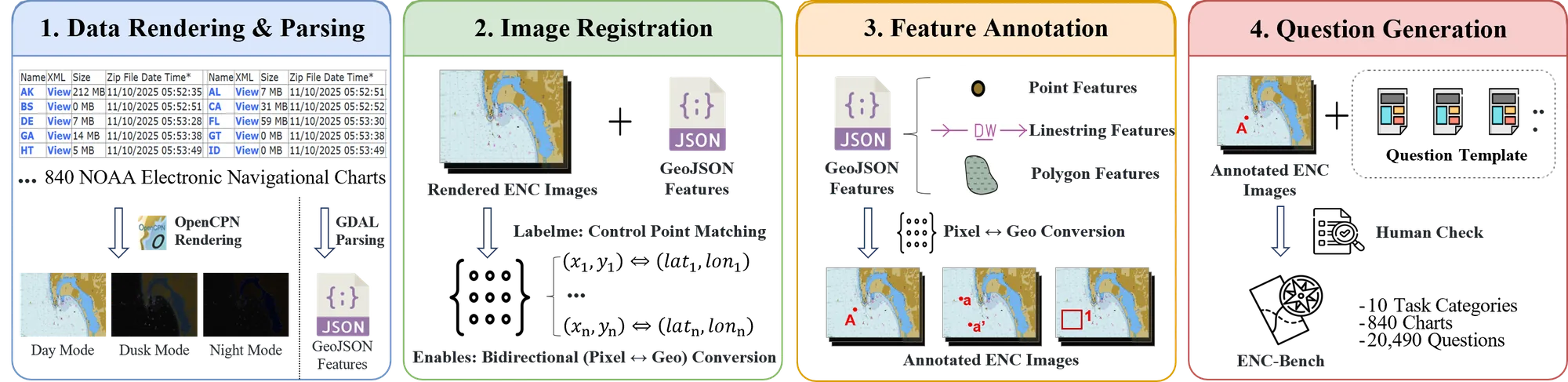
All samples are generated from raw S-57 data through a calibrated vector-to-image
pipeline with automated consistency checks and expert review.
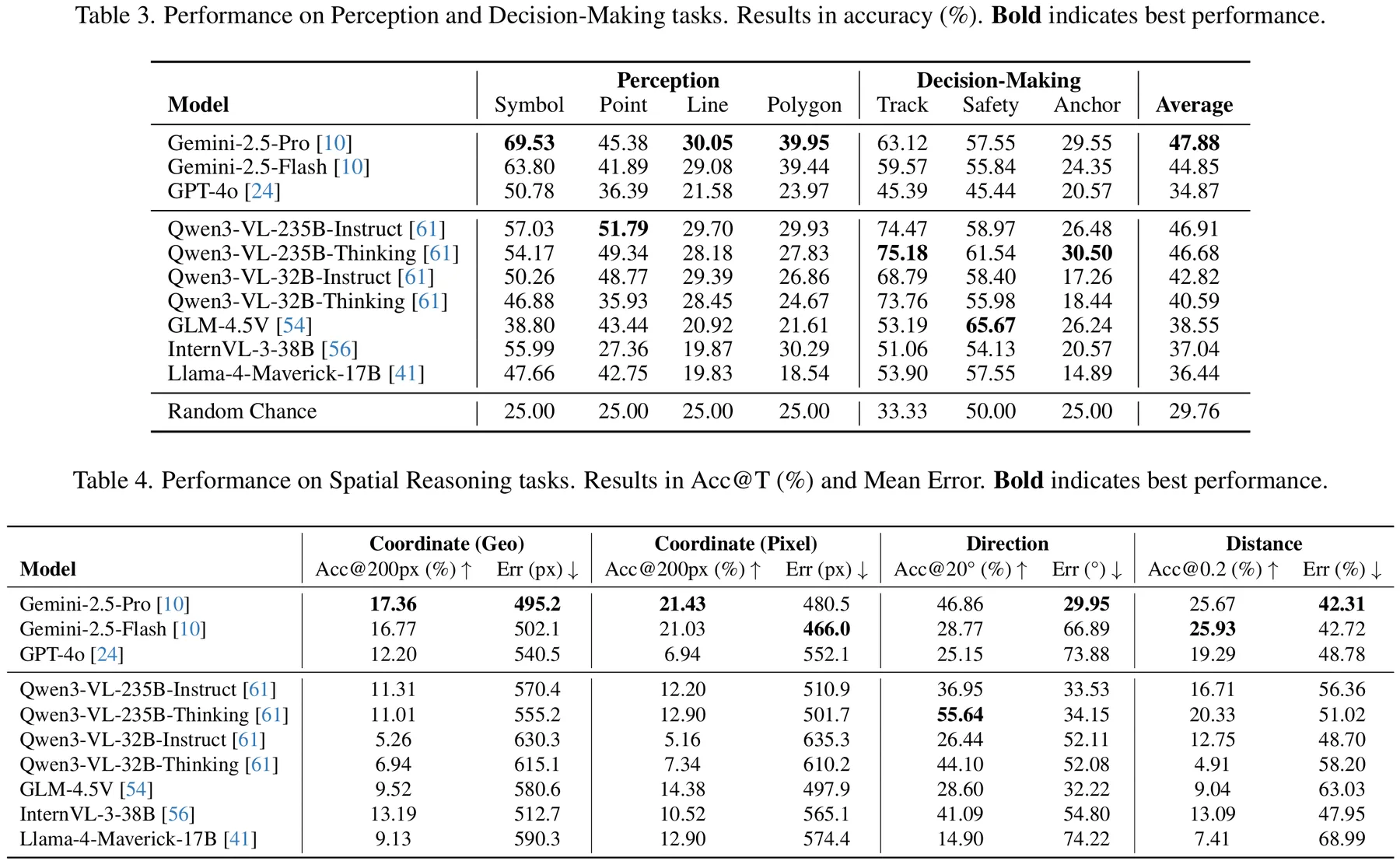
We evaluate 10 state-of-the-art MLLMs such as GPT-4o, Gemini 2.5, Qwen3-VL,
InternVL3, and GLM-4.5V under a unified zero-shot protocol. The best model achieves
only 47.88% accuracy, with systematic challenges in symbolic grounding,
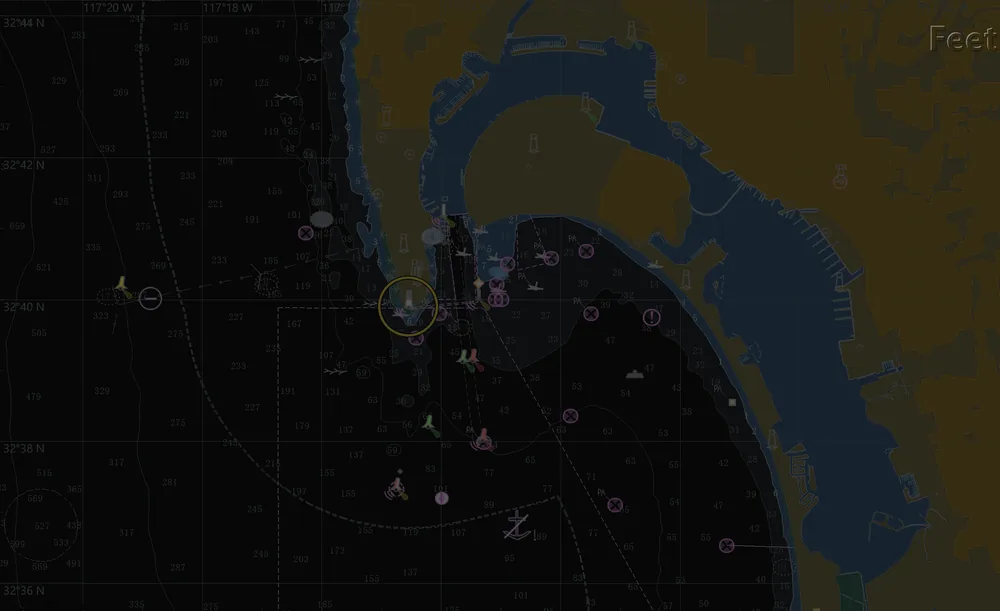
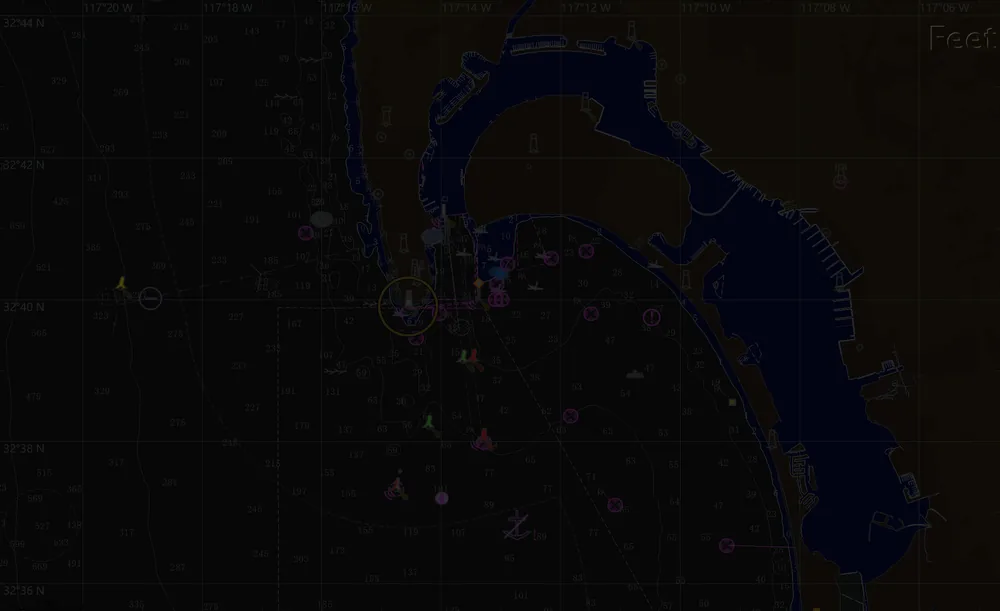
spatial computation, multi-constraint reasoning, and robustness to lighting and scale
variations. By establishing the first rigorous ENC benchmark, we open a new research
frontier at the intersection of specialized symbolic reasoning and safety-critical AI.